Project Overview (Fall 2019)
The class project in CS7637: Knowledge-Based AI involves constructing an AI agent to address a human intelligence test. The overall process is the same across all three projects; what differs is the complexity of the problems (and their representations) that your agent will address. So, this document is long, but it is effectively the directions for all three projects of this semester.
In a (Large) Nutshell
The CS7637 class project is to create an AI agent that can pass a human intelligence test. You’ll download a code package that contains the boilerplate necessary to run an agent you design against a set of problems inspired by the Raven’s Progressive Matrices test of intelligence. Within it, you’ll implement the Agent.java or Agent.py file to take in a problem and return an answer.
There are four sets of problems for your agent to answer: B, C, D, and E. Each set contains four types of problems: Basic, Test, Challenge, and Raven’s. You’ll be able to see the Basic and Challenge problems while designing your agent, and your grade will be based on your agent’s answers to the Basic and Test problems. Each project will add a problem set or two: on Project 1, your agent will answer set B; on Project 2, your agent will answer sets B and C; and on Project 3, your agent will answer sets B, C, D, and E. Thus, Projects 1 and 2 build toward Project 3, the ultimate deliverable. Your grade will be based on three components: how well your agent performs on the problems, how your agent is implemented and revised, and a project reflection you turn in along with your agent.
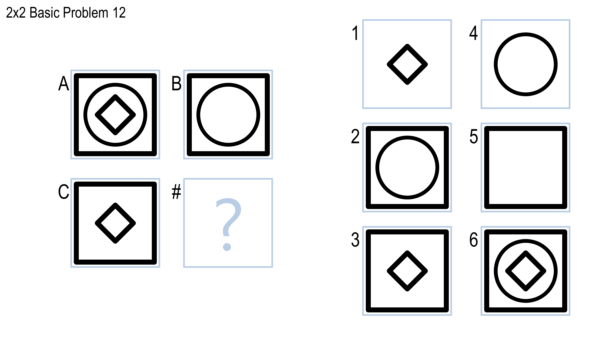
Different problems will also give your agent different amounts of information. Certain problems in problem sets B and C (specifically, the Basic and Test problems) will provide “verbal” representations. Verbal representations are structured representations that verbally describe what’s inside a figure in a problem. For example, in the problem below, a verbal representation would describe figure B as “a large, unfilled circle inside a very large, unfilled square”, and figure C as “a small, unfilled, rotated square inside a very large, unfilled square”, using a more structure representation. Your agent would take those descriptions and produce an answer from the eight choices. In all the other problem sets, however, your agent will only be given the images themselves — what we call a “visual” representation — in .png format. It will have to take in the image of the figures themselves and do its reasoning based on those.
Every problem set provides visual representations, so you can try approaching these problems using visual representations (instead of or in addition to using verbal representations) as early as you want. Project 3’s problem sets (D and E) only provide visual representations, so you’ll have to try a visual approach eventually. However, verbal approaches tend to be somewhat easier because a human has already interpreted the figure, so you may find it best to rely mostly on the verbal representations for the first two projects. Note that all the optional problems (the Challenge and Raven’s problems) only provide visual representations, so if you want to try those problems during Projects 1 and 2, you’ll want to try a visual approach then. Your agent will run against every problem on Project 3, though, so you’ll never miss out on the chance to give those a try.
Don’t worry if the above doesn’t make sense quite yet — the projects are a bit complex when you’re getting started. The goal of this section is just to provide you with a high-level view so that the rest of this document makes a bit more sense.
Background and Goals
This section covers the learning goals and background information necessary to understand the projects.
Learning Goals
One goal of Knowledge-Based Artificial Intelligence is to create human-like, human-level intelligence. If this is the goal of the field, then what better way to evaluate intelligence of an agent than by having it take the same intelligence tests that humans take?
There are numerous tests of human intelligence, but one of the most reliable and commonly-used is Raven’s Progressive Matrices. Raven’s Progressive Matrices, or RPM, are visual analogy problems where the test-taker is given a matrix of figures and asked to select the figure that completes the matrix. An example of a 2x2 problem was shown above; an example of a 3x3 problem is shown below.

In these projects, you will design agents that will address RPM-inspired problems such as the ones above. The goal of this project is to authentically experience the overall goals of knowledge-based AI: to design an agent with human-like, human-level intelligence; to test that agent against a set of authentic problems; and to use that agent’s performance to reflect on what we believe about human cognition. As such, you might not use every topic covered in KBAI on the projects; the topics covered give a bottom-up view of the topics and principles KBAI, while the project gives a top-down view of the goals and concepts of KBAI.
About the Test
The full Raven’s Progressive Matrices test consists of 60 visual analogy problems divided into five sets: A, B, C, D, and E. Set A is comprised of 12 simple pattern-matching problems which we won’t cover in these projects. Set B is comprised of 12 2x2 matrix problems, such as the first image shown above. Sets C, D, and E are each comprised of 12 3x3 matrix problems, such as the second image shown above. Problems are named with their set followed by their number, such as problem B-05 or C-11. The sets are of roughly ascending difficulty.
{kind=link}
For copyright reasons, we cannot provide the real Raven’s Progressive Matrices test to everyone. Instead, we’ll be giving you sets of problems — which we call “Basic” problems — inspired by the real RPM to use to develop your agent. Your agent will be evaluated based on how well it performs on these “Basic” problems, as well as a parallel set of “Test” problems that you will not see while designing your agent. These Test problems are directly analogous to the Basic problems; running against the two sets provides a check for generality and overfitting. Your agents will also run against the real RPM as well as a set of Challenge problems, but neither of these will be factored into your grade.
Overall, by Project 3, your agent will answer 192 problems. More on the specific problems that your agent will complete are in the sections that follow.
Verbal vs. Visual
Historically in the community, there have been two broad categories of approaches to RPM: verbal and visual. Verbal approaches attempt to solve RPM based on verbal representations of the problems. In these representations, a human initially describes the contents of the figures of a problem using a formal vocabulary, and an AI agent then reasons over those representations. Visual approaches, on the other hand, attempt to solve RPM based strictly on the images themselves: they take as input the raw image data and perform their analysis from there. Examples of verbal approaches include Carpenter, Just & Shell 1990 and Lovett, Forbus & Usher 2009. Examples of visual approaches include Kunda, McGreggor & Goel 2013 and McGreggor & Goel 2014.
Much research has been done examining the differences between these approaches in humans (e.g. Brouwers, Vijver & Hemert 2009). Within artificial intelligence, visual approaches are generally more robust in that an initial phase of human reasoning is not necessary. Thus, the ultimate goal for these projects will be to solve RPM-inspired problems visually. However, visual problem-solving tends to be significantly more difficult. Thus, you will start by having the option to use both verbal and visual approaches (using verbal representations we have produced for you), and by the last project you will use only visual methods.
Details & Deliverables
This section covers the more specific details of the projects: what you will deliver, what problems your agents will solve, and what representations will be given to you.
Project Progression
In this offering of CS7637, you will complete three projects:
- Project 1: Problem set B
- Project 2: Problem set C
- Project 3: Problem sets D and E
Each problem set consists of 48 problems: 12 Basic, 12 Test, 12 Raven’s, and 12 Challenge. Only Basic and Test problems will be used in determining your grade. The Raven’s problems are run for authenticity and analysis, but are not used in calculating your grade. Note that each project will also be run on the previous projects’ problem sets, but not for a grade: this is just for you to see how your agent improves over time. So, Project 3 will run on all 192 problems (48 Basic, 48 Test, 48 Raven’s, and 48 Challenge), but only the 48 problems in sets D and E will be used for your grade.
On each project, you will have access to the Basic and Challenge problems while designing and testing your agent; you will not have access to the Test or Raven’s problems while designing and testing your agent. Challenge and Raven’s problems are not part of your grade, though note that the Challenge problems will often be used to expose your agent to extra properties and shapes seen on the real Raven’s problems that are not covered in the Basic and Test problems.
As mentioned previously, the problems themselves ascend in difficulty from set to set. Additionally, only visual representations will be given for problem sets D and E, so for project 3 you’ll be required to do some visual reasoning.
For each project, your code must be submitted to the autograder by the deadline. However, it is okay if your project is still running after the deadline. You are only permitted 10 submissions per project.
On each project, you will also complete a project reflection describing your process of constructing your agent, your agent’s performance and limitations, and your agent’s connection to human cognition.
Grading
Your grade on the project is based on three criteria: your agent’s performance on the Basic and Test problems (30%), your agent’s implementation and revision (20%), and the project reflection you submit along with your agent (50%).
Performance
For performance, your agent will be graded on whether it meets minimum performance goals. The minimum performance goal is: 7 or more problems correct on each set of 12 problems. The Basic and Test sets are each worth 15%: meeting the minimum goal on both earns the full 30%, while meeting the goal on only one earns 15%. Meeting the goal on neither earns 0%. (For Project 3, where there are four sets instead of two, each is worth 7.5%.)
Note that we will use your best submissions to calculate these scores. Your best scores on each set do not need to come on the same submission. For example, if you reached 7/12 on the Basic B set on your third submission and 7/12 on the Test B set on your fifth submission, but never reached 7/12 on either set on any other submission, you would still receive full credit.
Revise & Reflect
For implementation and revision, we will look at the implementation of your agent as well as your patterns of revision. We expect you to run your code on the server relatively often: this is how we will judge your revision process. This area is more subjective, but generally, you will receive credit as long as (a) your agent reaches perfect performance on Basic and Test problems, (b) your agent gets better over a series of a few submissions, even if it never reaches perfection, or (c) you keep trying and making non-trivial revisions, even if your agent’s performance is not getting better. In other words, you’ll receive credit for a successful agent or continued attempts to build a successful agent.
You should notice that between Performance and Revise & Reflect, there is no heavy incentive to design a near-perfect agent at all costs. This is intentional: we want you to design agents that are somewhat successful, but beyond that, we care more about novel and interesting approaches than about success-at-all-costs approaches.
Journal
For the journal, you will write a personal reflection on your process of constructing the agent. It will include an introduction and conclusion, as well as a journal entry for each individual submission to the autograder. In each journal entry, you should include the submission to which the entry corresponds, a description of what has changed, a reflection on the relationship between your latest agent and human cognition, and a reflection on the agent’s performance.
Revise & Reflect and Journal credit are deeply intertwined: you’ll know that you’re fulfilling our goals for implementation if you find you have plenty to write about in your journal.
Top Performers
As noted, project grading specifically encourages either having a great agent or continually trying to improve your agent. Someone whose agent works perfectly on their first submission will receive the same implementation score as someone whose agent slowly gets better over a series of several submissions, even if they never come close to perfect performance.
However, we do want to have some incentive for doing well. Thus, on each of the three projects, the top 10 performers in the class will receive 5 extra points on their final average. This effectively means they can skip a test (or a couple questions on a homework, or some participation), or just let the extra points compensate for lost points elsewhere in the class.
Note that a single student can only receive this once; students who already received this bonus on an earlier project will be skipped in finding the top 10 on a later project. Top 10 will be calculated by total score on the problems graded for that project (e.g. Basic B and Test B for Project 1; Basic C and Test C for Project 2). If necessary, ties will be broken first by performance on the Raven’s problems, then on the Challenge problems.
Getting Started
To make it easier to start the project and focus on the concepts involved (rather than the nuts and bolts of reading in problems and writing out answers), you’ll be working from an agent framework in your choice of Python or Java. You can get the framework in one of two ways:
- Clone it from the master repository with ‘git clone –recurse-submodules https://github.gatech.edu/Dilab/KBAI-package-java.git’ (Java) or ‘git clone —-recurse-submodules https://github.gatech.edu/Dilab/KBAI-package-python.git’ (Python). This makes it easier to ‘git pull’ any (rare) framework changes or fixes that must be made after the project is released.
- Download Project-Code-Java or Project-Code-Python as a zip file from this folder. This method allows you to obtain the code if you are having trouble accessing the Georgia Tech Github site.
You will place your code into the Solve method of the Agent class supplied. You can also create any additional methods, classes, and files needed to organize your code; Solve is simply the entry point into your agent.
The Problem Sets
As mentioned previously, in project 3, your agent will run against 192 problems: 4 sets of 48 problems, with each set further broken down into 4 categories with 12 problems each. The table below gives a rundown of the 16 smaller sets, what will be provided for each, and when your agent will approach each.
Key:
- P1?, P2?, and P3?: Whether that set will be used on that project.
- Graded?: Whether your agent’s performance on that set will be used in determining your grade for the project (Basic and Test are used for grading, Challenge and Raven’s are just used for authenticity and curiosity).
- Provided?: Whether you’ll be given a copy of those problems to use in designing your agent (you’ll see Basic and Challenge problems, but Test and Raven’s will remain hidden).
- Visual?: Whether your agent will have access to visual representations of the set (which it will for all problems).
- Verbal?: Whether your agent will have access to verbal representations of the set (you’ll have verbal representations for sets B and C, but not for sets D and E).
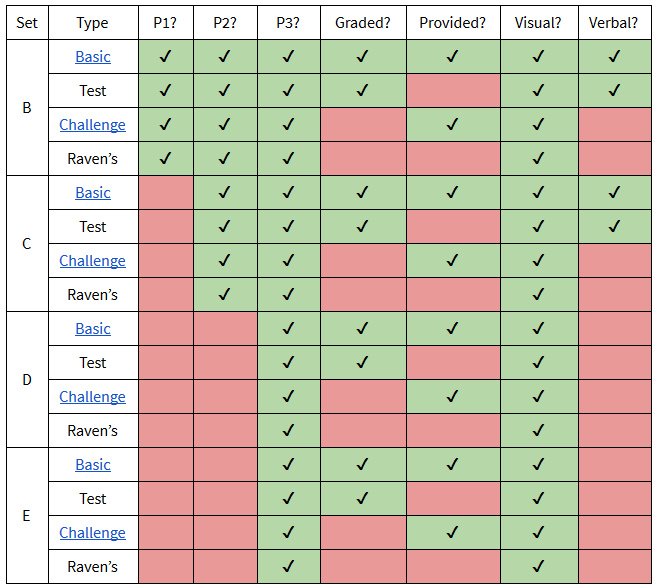
Thus, for the first two projects, you’ll be addressing the easier two sets of problems using visual and/or verbal representations. For the final project, you’ll address the final two sets of problems using their visual representations only. It might, therefore, be prudent to get an early start on the visual methods!
Within each set, the Basic, Test, and Raven’s problems are constructed to be roughly analogous to one another. The Basic problem is constructed to mimic the relationships and transformations in the corresponding Raven’s problem, and the Test problem is constructed to mimic the Basic problem very, very closely. So, if you see that your agent gets Basic problem B-05 correct but Test and Raven’s problems B-05 wrong, you know that might be a place where your agent is either overfitting or getting lucky. This also means you can anticipate your agent’s performance on the Test problems relatively well: each Test problem uses a near-identical principle to the corresponding Basic problem. In the past, agents have averaged getting 85% as many Test problems right as Basic problems, so there’s a pretty good correlation there if you’re using a robust, general method.
The Problems
You are provided with the Basic and Challenge problems to use in designing your agent. The Test and Raven’s problems are hidden and will only be used when grading your project. This is to test your agents for generality: it isn’t hard to design an agent that can answer questions it has already seen, just as it would not be hard to score well on a test you have already taken before. However, performing well on problems you and your agent haven’t seen before is a more reliable test of intelligence. Your grade is based solely on your agent’s performance on the Basic and Test problems.
All problems are contained within the Problems folder of the downloadable. Problems are divided into sets, and then into individual problems. Each problem’s folder has three things:
- The problem itself, for your benefit.
- A ProblemData.txt file, containing information about the problem, including its correct answer, its type, and its verbal representation (if applicable).
- Visual representations of each figure, named A.png, B. png, etc.
You should not attempt to access ProblemData.txt directly; its filename will be changed when we grade projects. Generally, you need not worry about this directory structure; all problem data will be loaded into the RavensProblem object passed to your agent’s Solve method, and the filenames for the different visual representations will be included in their corresponding RavensFigures.
Working with the Code
The framework code is available here as Project-Code-Java.zip or Project-Code-Python.zip. Both are also available from git via ‘git clone –recursive https://github.gatech.edu/Dilab/KBAI-package-java.git’ (Java) or ‘git clone –recursive https://github.gatech.edu/Dilab/KBAI-package-python.git’ respectively. Note that these code packages contain a file instructing your agent to only look at those problems relevant for Project 1; updated versions of this file will be supplied for Project 2 and Project 3.
The Code
The downloadable package has a number of either Java or Python files: RavensProject, ProblemSet, RavensProblem, RavensFigure, RavensObject, and Agent. Of these, you should only modify the Agent class. You may make changes to the other classes to test your agent, write debug statements, etc. However, when we test your code, we will use the original versions of these files as downloaded here. Do not rely on changes to any class except for Agent to run your code. In addition to Agent, you may also write your own additional files and classes for inclusion in your project.
In Agent, you will find two methods: a constructor and a Solve method. The constructor will be called at the beginning of the program, so you may use this method to initialize any information necessary before your agent begins solving problems. After that, Solve will be called on each problem. You should write the Solve method to return its answer to the given question:
- 2x2 questions have six answer options, so to answer the question, your agent should return an integer from 1 to 6.
- 3x3 questions have eight answer options, so your agent should return an integer from 1 to 8.
- If your agent wants to skip a question, it should return a negative number. Any negative number will be treated as your agent skipping the problem.
You may do all the processing within Solve, or you may write other methods and classes to help your agent solve the problems.
When running, the program will load questions from the Problems folder. It will then ask your agent to solve each problem one by one and write the results to ProblemResults.csv. You may check ProblemResults.csv to see how well your agent performed. You may also check SetResults.csv to view a summary of your agent’s performance at the set level.
The Documentation
Included in the downloadable is the documentation for interacting with the code (API/index.html in the downloadable). You may use this and the in-line comments to understand the structure of the problems. Briefly, however:
- RavensProject: The main driver of the project. This file will load the list of problem sets, initialize your agent, then pass the problems to your agent one by one.
- RavensGrader: The grading file for the project. After your agent generates its answers, this file will check the answers and assign a score.
- Agent: The class in which you will define your agent. When you run the project, your Agent will be constructed, and then its Solve method will be called on each RavensProblem. At the end of Solve, your agent should return an integer as the answer for that problem (or a negative number to skip that problem).
- ProblemSet: A list of RavensProblems within a particular set.
- RavensProblem: A single problem, such as the one shown earlier in this document. This is the most complicated and important class in the project, so let’s break it into parts. RavensProblem includes:
- A HashMap (Java) or Dictionary (Python) of the individual Figures (that is, the squares labeled “A”, “B”, “C”, “1”, “2”, etc.) from the problem. The RavensFigures associated with keys “A”, “B”, and “C” are the problem itself, and those associated with the keys “1”, “2”, “3”, “4”, “5”, and “6” are the potential answer choices.
- A String representing the name of the problem and a String representing the type of problem (“2x2” or “3x3”).
- Variables hasVisual and hasVerbal indicating whether that problem has a visual or verbal representation (all problems this semester have visual representations, only some have verbal representations).
- RavensFigure: A single square from the problem, labeled either “A”, “B”, “C”, “1”, “2”, etc. All RavensFigures have a filename referring to the visual representation (in PNG form) of the figure’s contents. Problems with verbal representations also contain dictionaries of RavensObjects. In the example above, the squares labeled “A”, “B”, “C”, “1”, “2”, “3”, “4”, “5”, and “6” would each be separate instances of RavensFigure, each with a list of RavensObject.
- RavensObject: A single object, typically a shape such as a circle or square, within a RavensFigure. For example, in the problem above, the Figure “C” would have one RavensObject, representing the square in the figure. RavensObjects contain a name and a dictionary of attributes. Attributes are key-value pairs, where the key is the name of some general attribute (such as ‘size’, ‘shape’, and ‘fill’) and the value is the particular characteristic for that object (such as ‘large’, ‘circle’, and ‘yes). For example, the square in figure “C” could have three RavensAttributes: shape:square, fill:no, and size:very large. Generally, but not always, the representation will provide the shape, size, and fill attributes for all objects, as well as any other relevant information for the particular problem.
The documentation is ultimately somewhat straightforward, but it can be complicated when you’re initially getting used to it. The most important things to remember are:
- Every time Solve is called, your agent is given a single problem. By the end of Solve, it should return an answer as an integer. You don’t need to worry about how the problems are loaded from the files, how the problem sets are organized, or how the results are printed. You need only worry about writing the Solve method, which solves one question at a time.
- RavensProblems have a dictionary of RavensFigures, with each Figure representing one of the image squares in the problem and each key representing its letter (squares in the problem matrix) or number (answer choices). All RavensFigures have filenames so your agent can load the PNG with the visual representation. If the problem has a verbal representation as well (hasVerbal or hasVerbal() is true), then each RavensFigure has a dictionary of RavensObjects, each representing one shape in the Figure (such as a single circle, square, or triangle). Each RavensObject has a dictionary of attributes, such as “size”:“large”, “shape”:“triangle”, and “fill”:“yes”.
Libraries
No external libraries are permitted in Java. In Python, the only permitted libraries are the latest version of the Python image processing library Pillow and the latest version of numpy. For installation instructions on Pillow, see this page. For installation instructions on numpy, see this page. No other libraries are permitted.
Image Processing
Generally, we do not allow external libraries. For Java, you may use anything contained within the default Java 8 installation. Java 8 has plenty of image processing options. We recommend using BufferedImage, and we have included a bit of sample code below for loading images into BufferedImage. If you have other suggestions, please bring them up on Piazza!
Python has no native support for image processing, so an external library must be used. The only external library we support for image processing for Python is Pillow. You can install pillow simply by running easy_install pillow. More comprehensive information on installing Pillow can be found here. We have included a code segment below on loading an image from a file with Pillow.
Submitting Your Code
This class uses a server-side autograder to evaluate your submission. This means you can see how your code is performing against the Test problems even without seeing the problems themselves. Note that we will look at your submission history when evaluating your implementation: we want to see that you modified your agent over time, either to try to improve its performance or to experiment with different approaches. So, you should submit early and often. However, you are limited to 10 submissions per project to avoid over-stressing the autograder and to disincentivize “brute force” methods for solving the problems.
Below are the step-by-step submission instructions for submitting your agent to the autograder.
Getting Started with the Autograder
First, make sure your agent is built using the official framework. Follow the instructions under Working with the Code.
Then, install a couple of packages required for running the submit script by running:
pip install requests future
If you are using Python 3, please update the language.txt file to say ‘python3’ instead of ‘python’.
In your project directory (for either language) you will find a Python script called submit.py. When running it, two parameters must be provided: provider and assignment. provider should always be gt: `–provider gt`. For assignment, the available parameters are P1, P2, P3, error-check, error-check-2, and error-check-3. P1, P2, and P3 submit your code against the corresponding project. error-check, error-check-2 (for P2) and error-check-3 (for P3) submit your code just for a preemptive check to make sure it is properly formatted and runnable by the autograder. We strongly recommend you first run the error check:
python submit.py --provider gt --assignment error-check
Note that this does not count as a project submission and will not be graded. It only ensures that your code is properly formatted and ready for grading prior to real submission so that you don’t waste a submission on broken code.
Submitting a Project
To submit project 1 for credit, run:
python submit.py --provider gt --assignment P1
Note that running this command will count against your submission limit for P1.
If you have created additional files, make sure to include them with the –files parameter. For example, if you are submitting project 1 built in Java and your agent uses two extra classes called RavensTransform and RavensNetwork, you would run:
python submit.py --provider gt --assignment P1 --files RavensTransform.java RavensNetwork.java
Note that it is not necessary to explicitly list all the files included in the project framework.
Logging In
The script will prompt you for your login information. Make sure to use your Georgia Tech login credentials so that we can credit you for your submission! Optionally, you can save your login information when the script prompts you to “save jwt” — this will avoid the need to re-enter it on future runs.
Note: if you are using two-factor authentication, an additional step is required to allow the submit script to log in on your behalf — please see the instructions at https://bonnie.udacity.com/auth_tokens/two_factor.
Getting Your Results
The script will run for a while and then return a set of results which looks something like this:
Problem,Correct?,Correct Answer,Agent's Answer "Challenge Problem B-04",0,4,1 "Basic Problem B-12",1,1,1 ...
It will also display some summary information per problem set in the console. You may find it convenient to open the CSV-formatted results in a spreadsheet program like Excel for easy browsing and reference. The autograder will not provide you your code’s own output or access to any files your code generates in order to prevent leaking information.
You can check the number of submissions you have remaining (as well as some other fun statistics about your agent) at https://bonnie.udacity.com/.
Submission Errors
If your submission errors out, you’ll see a result indicating what kind of error the code encountered. (For Java, this will be either a build or an execution error; since Python is an interpreted language, only execution errors are possible.)
Here are some debugging steps you can try:
- If you have a build error in Java, try running ‘cd workspace/ravensproject; javac @sources.txt’ to build at the command line. This is the same command we use to build your code, and running it should give you an exact file/line where the build error occurs.
- If you have an execution error in Python, make sure that your language.txt file reflects the actual Python version you are running locally. If you’re using an IDE like IntelliJ, your project settings should tell you what interpreter you’re using. If you’re running at the command line, you can find the interpreter version with ‘python –version’. Usually, if you’re running ‘python’ it’s Python 2, and if you’re running ‘python3’ it’s Python 3. Similarly, you should update language.txt to say ‘python’ for Python 2 and ‘python3’ for Python 3.
- If your agent results are different than expected (e.g., you get a different score on Basic and Challenge sets when you run locally), double-check the language.txt again! If that’s correct, check to see if your local library versions match the ones on the autograder; those are:
- Java: JDK 8u73
- Python 3: Python 3.4.3
- Python 2: Python 2.7.11
- Pillow: Pillow 3.1.1
- Numpy: 1.10
- If you get a message containing the text “The total output length exceeded the limit of 65536 bytes.”, your agent is dumping too much output to stdout. Try removing print/log statements before you resubmit.
- If you include a class named RavensSolver and get an error about it, rename it to something else and resubmit – this class name is used by the autograder.
- If the submission script hangs without asking you for credentials, or after asking you for your username but before asking you for your password, check what shell you’re using. We have seen this issue occasionally with Windows users who are attempting to submit from the git shell or Cygwin. If you are using one of these, try resubmitting from the standard command prompt.
If you encounter any problems at all when running the autograder, please post to Piazza in the autograder folder. This helps make sure we’ll see your issue and respond promptly!
Relevant Resources
Goel, A. (2015). Geometry, Drawings, Visual Thinking, and Imagery: Towards a Visual Turing Test of Machine Intelligence. In Proceedings of the 29th Association for the Advancement of Artificial Intelligence Conference Workshop on Beyond the Turing Test. Austin, Texas.
McGreggor, K., & Goel, A. (2014). Confident Reasoning on Raven’s Progressive Matrices Tests. In Proceedings of the 28th Association for the Advancement of Artificial Intelligence Conference. Québec City, Québec.
Kunda, M. (2013). Visual problem solving in autism, psychometrics, and AI: the case of the Raven’s Progressive Matrices intelligence test. Doctoral dissertation.
Emruli, B., Gayler, R. W., & Sandin, F. (2013). Analogical mapping and inference with binary spatter codes and sparse distributed memory. In Neural Networks (IJCNN), The 2013 International Joint Conference on. IEEE.
Little, D., Lewandowsky, S., & Griffiths, T. (2012). A Bayesian model of rule induction in Raven’s progressive matrices. In Proceedings of the 34th Annual Conference of the Cognitive Science Society. Sapporo, Japan.
Kunda, M., McGreggor, K., & Goel, A. K. (2012). Reasoning on the Raven’s advanced progressive matrices test with iconic visual representations. In 34th Annual Conference of the Cognitive Science Society. Sapporo, Japan.
Lovett, A., & Forbus, K. (2012). Modeling multiple strategies for solving geometric analogy problems. In 34th Annual Conference of the Cognitive Science Society. Sapporo, Japan.
Schwering, A., Gust, H., Kühnberger, K. U., & Krumnack, U. (2009). Solving geometric proportional analogies with the analogy model HDTP. In 31st Annual Conference of the Cognitive Science Society. Amsterdam, Netherlands.
Joyner, D., Bedwell, D., Graham, C., Lemmon, W., Martinez, O., & Goel, A. (2015). Using Human Computation to Acquire Novel Methods for Addressing Visual Analogy Problems on Intelligence Tests. In Proceedings of the Sixth International Conference on Computational Creativity. Provo, Utah.
…and many more!